系列1 简介
出品 | 磐创AI技术团队
【磐创AI导读】本文是深度学习之视频人脸识别系列的第一篇文章,介绍了人脸识别领域的一些基本概念,分析了深度学习在人脸识别的基本流程,并总结了近年来科研领域的研究进展,最后分析了静态数据与视频动态数据在人脸识别技术上的差异。欢迎大家点击上方篮子关注我们的公众号:磐创AI。
一、基本概念
1. 人脸识别(face identification)
人脸识别是1对n的比对,给定一张人脸图片,如何在n张人脸图片中找到同一张人脸图片,相对于一个分类问题,将一张人脸划分到n张人脸中的一张。类似于管理人员进行的人脸识别门禁系统。
2.人脸验证(face verification)
人脸验证的1对1的比对,给定两张人脸图片,判断这两张人脸是否为同一人,类似于手机的人脸解锁系统,事先在手机在录入自己的脸部信息,然后在开锁时比对摄像头捕捉到的人脸是否与手机上录入的人脸为同一个人。
3.人脸检测(face detection)
人脸检测是在一张图片中把人脸检测出来,即在图片上把人脸用矩形框出来,并得到矩形的坐标,如下图所示。

4. 人脸关键点检测
根据输入的人脸图像,识别出面部关键特征点,如眼睛、鼻尖、嘴角点、眉毛以及人脸各部件轮廓点的坐标,如下图所示。
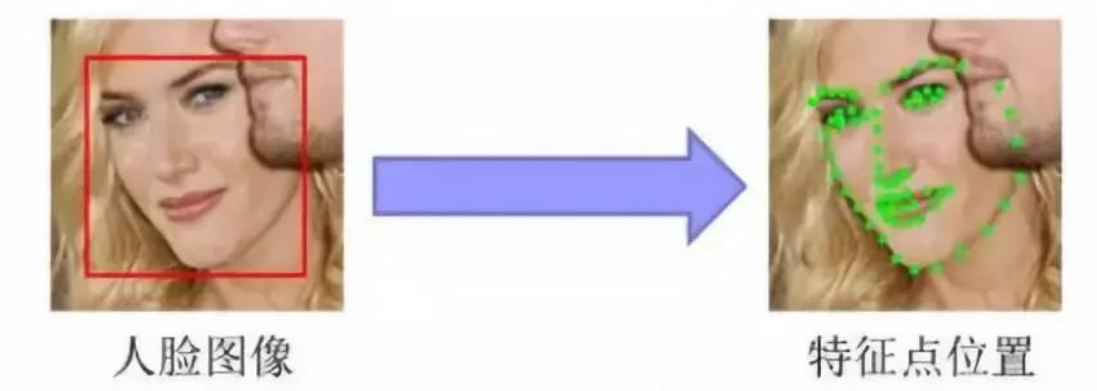
5. 人脸矫正(人脸对齐)
通过人脸关键点检测得到人脸的关键点坐标,然后根据人脸的关键点坐标调整人脸的角度,使人脸对齐,由于输入图像的尺寸是大小不一的,人脸区域大小也不相同,角度不一样,所以要通过坐标变换,对人脸图像进行归一化操作,如下图所示。

二、基于深度学习的人脸识别算法基本流程
随着神经网络的迅速发展和其对图像数据的强大的特征提取,深度学习运用于人脸识别也成为热点研究方向;2014年的开山之作DeepFace,第一个真正将大数据和深度学习结合应用于人脸识别与验证,确立人脸识别的常规流程:图片->人脸与关键点检测->人脸对齐->人脸表征(representation)->分类。首先将图片中的人脸检测处理并通过关键点进行对齐,如何输入到神经网络,得到特征向量,通过分类训练过程,该向量即为人脸的特征向量。要求出两张人脸的相似度即计算两个特征的向量度量之差,方法包括:SVM、SiameseNetwork、JointBayesian、L1距离、L2距离、cos距离等。
三、科研领域近期进展
科研领域近期进展主要集中于loss函数的研究,包括DeepId2(Contrastive Loss)、FaceNet(Triplet loss)、L-Softmax、SphereFace(A-Softmax)、Center Loss、L2-Softmax、NormFace、CosFace(AM-Softmax)、ArcFace(AA-Softmax)等。
四、基于视频人脸识别和图片人脸识别的区别
(_该小结部分参考于博客园 - 米罗西http://www.cnblogs.com/zhehan54/p/6727631.html_)
相对于图片数据,目前视频人脸识别有很多挑战,包括:(1)视频数据一般为户外,视频图像质量比较差;(2)人脸图像比较小且模糊;(3)视频人脸识别对实时性要求更高。
但是视频数据也有一些优越性,视频数据同时具有空间信息和时间信息,在时间和空间的联合空间中描述人脸和识别人脸会具有一定提升空间。在视频数据中人脸跟踪是一个提高识别的方法,首先检测出人脸,然后跟踪人脸特征随时间的变化。当捕捉到一帧比较好的图像时,再使用图片人脸识别算法进行识别。这类方法中跟踪和识别是单独进行的,时间信息只在跟踪阶段用到。
【总结】:本期文章主要介绍了基于深度学习的人脸识别算法的一些基本入门知识,下一期我给大家介绍人脸识别中获取神经网络输入的算法,即关于人脸检测、人脸关键点检测与人脸对齐的一些重要算法和相关论文解析。
系列2 人脸检测与对齐
一、人脸检测与关键点检测
1. 问题描述:
人脸检测解决的问题为给定一张图片,输出图片中人脸的位置,即使用方框框住人脸,输出方框的左上角坐标和右下角坐标或者左上角坐标和长宽。算法难点包括:人脸大小差异、人脸遮挡、图片模糊、角度与姿态差异、表情差异等。而关键检测则是输出人脸关键点的坐标,如左眼(x1,y1)、右眼(x2,y2)、鼻子(x3,y3)、嘴巴左上角(x4,y4)、嘴巴右上角(x5,y5)等。
2. 深度学习相关算法:
(1)Cascade CNN
Cascade CNN源于发表于2015年CVPR上的一篇论文A Convolutional Neural Network Cascade for Face Detection【2】,作者提出了一种级连的CNN网络结构用于人脸检测。算法主体框架是基于V-J的瀑布流思想【1】,是传统技术和深度网络相结合的一个代表,Cascade CNN包含了多个分类器,这些分类器使用级联结构进行组织,与V-J不同的地方在于Cascade CNN采用卷积网络作为每一级的分类器。整个网络的处理流程如下图所示:
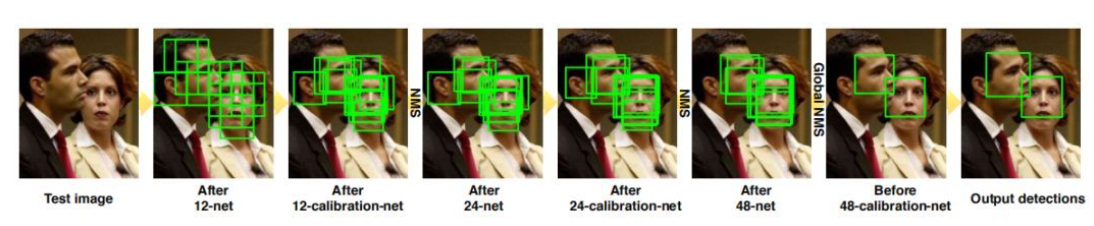
整个处理流程里包含了六个网络:12-net、12-calibration-net、24-net、24-calibration-net、48-net、48-calibration-net,其中三个二分类网络用于分类其是否为人脸,另外三个calibration网络用于矫正人脸框边界。其中第二个网络之后、第四个网络之后、第五个网络之后使用NMS算法过滤掉冗余的框。
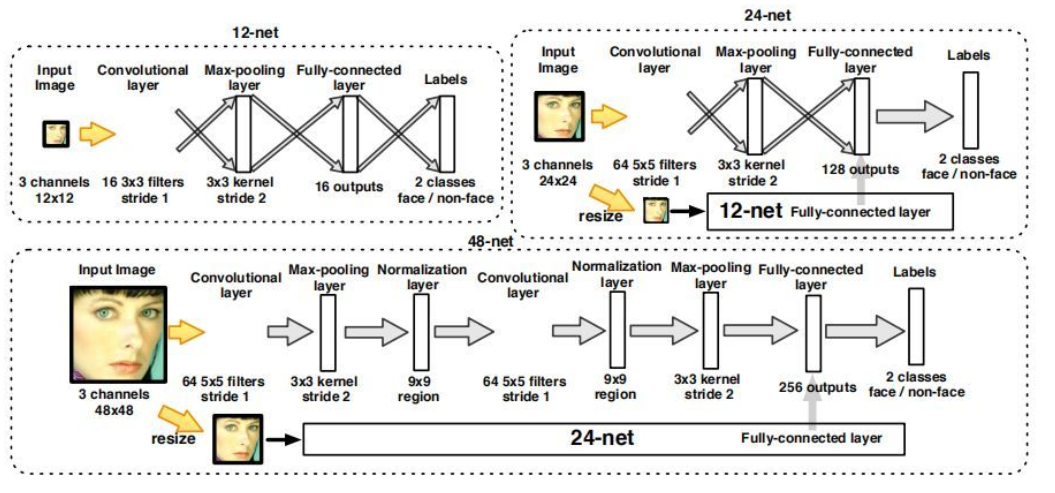
12-net,24-net和48-net的网络结构如下图所示:
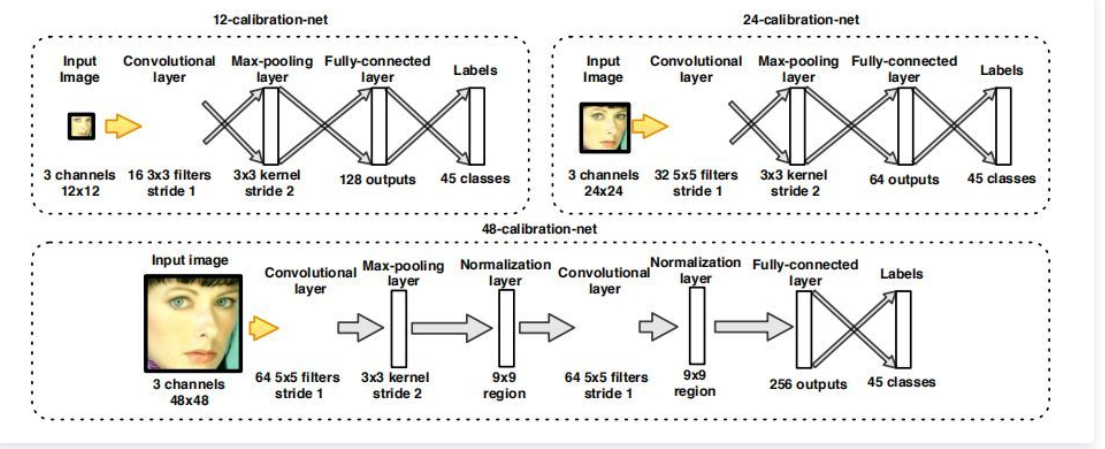
13-12-calibration-net,24-calibration-net,48-calibration-net的结构如下图所示:
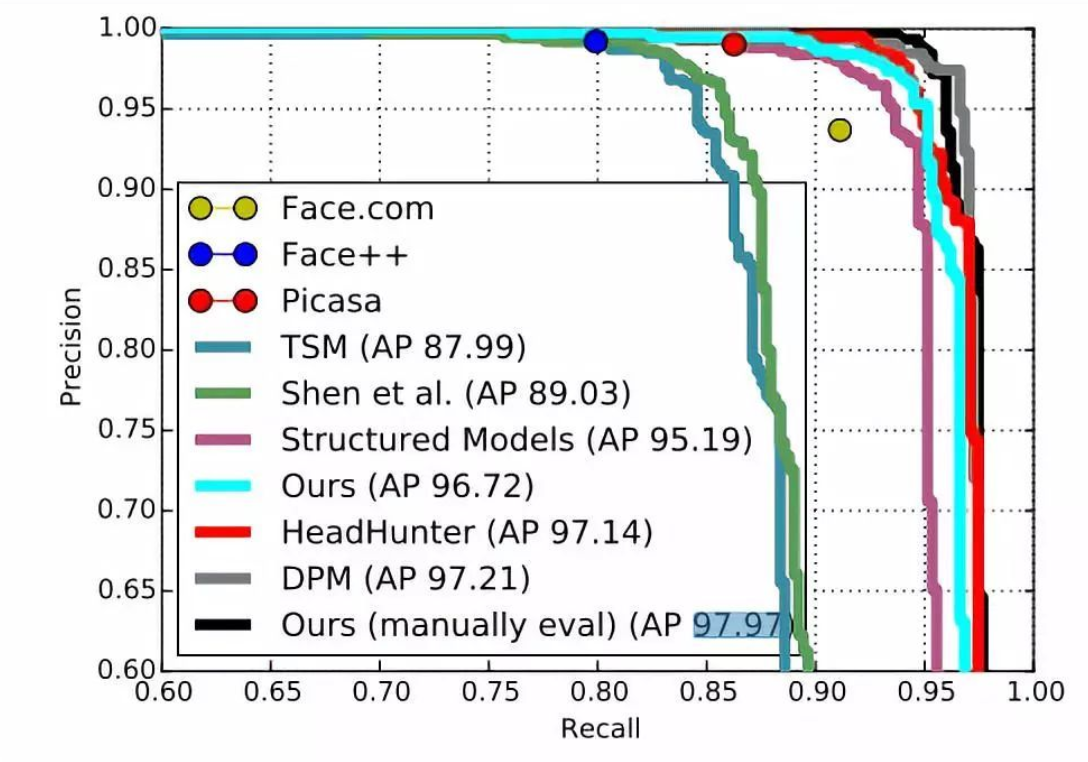
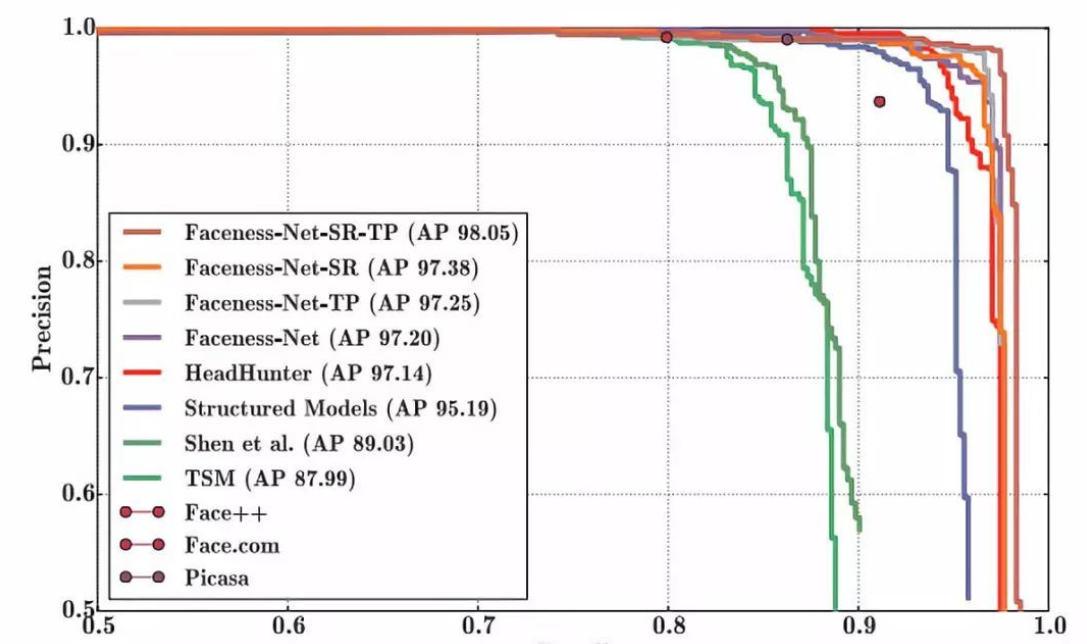
该算法结合了V-J框架构造了级连的CNN网络结构并设计边界矫正网络用来专门矫正人脸框边界,在AFW数据集上准确率达到97.97%。
(2)Faceness-Net
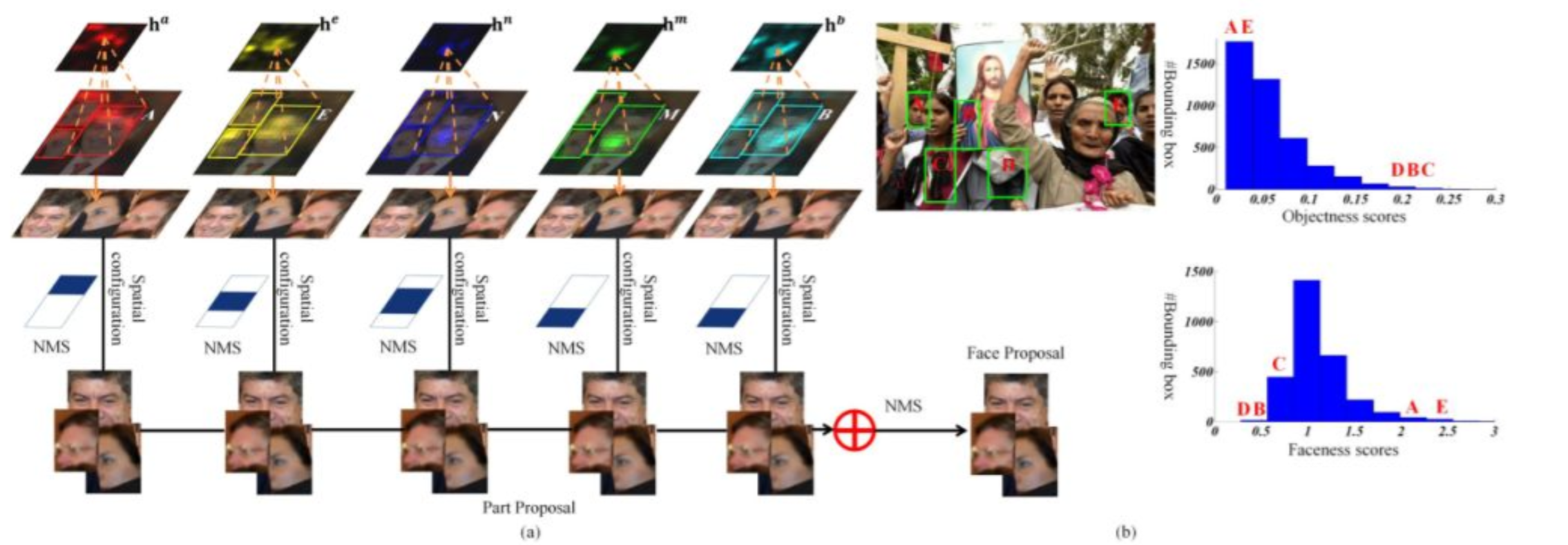
Faceness-Net源于论文A convolutional neural network cascade for face detection【3】,该算法基于DCNN网络【5】的人脸局部特征分类器,算法首先进行人脸局部特征的检测,使用多个基于DCNN网络的facial parts分类器对人脸进行评估,然后根据每个部件的得分进行规则分析得到Proposal的人脸区域,然后从局部到整体得到人脸候选区域,再对人脸候选区域进行人脸识别和矩形框坐标回归,该过程分为两个步骤。
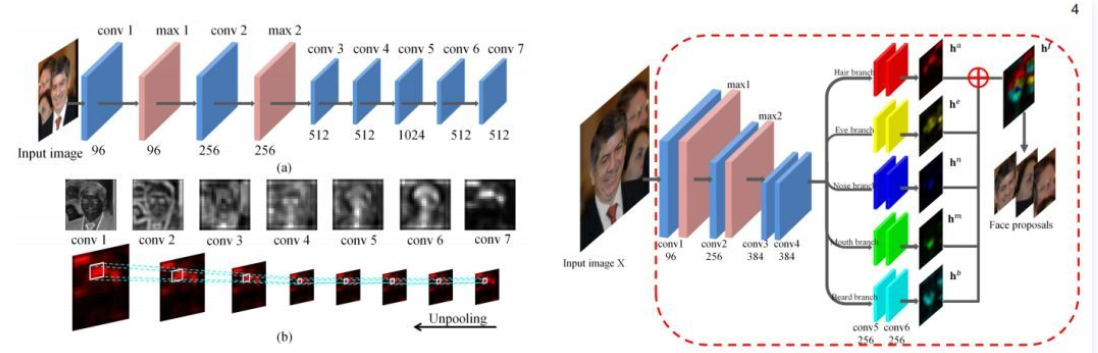
第一个步骤:每个人脸局部特征使用attribute-aware网络检测并生成人脸局部图,其中一共五个特征属性: 头发、眼睛、鼻子、嘴巴、胡子。然后通过人脸局部图根据评分构建人脸候选区域,具体如下图所示:
第二个步骤:训练一个多任务的卷积网络来完成人脸二分类和矩形框坐标回归,进一步提升其效果,具体如下图所示:
Faceness从脸部特征的角度来解决人脸检测中的遮挡和姿态角度问题,其整体性能在当时是非常好的,在AFW数据集上准确率可以达到98.05%。
(3)MTCNN
MTCNN源于论文Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks【6】,是基于多任务级联卷积神经网络来解决人脸检测和对齐问题,同时输出图片的人脸矩阵框和关键点坐标(左眼、右眼、鼻子、嘴巴左上角、嘴巴右上角)。MTCNN为三阶的级联卷积神经网络,整体框架如下图所示:
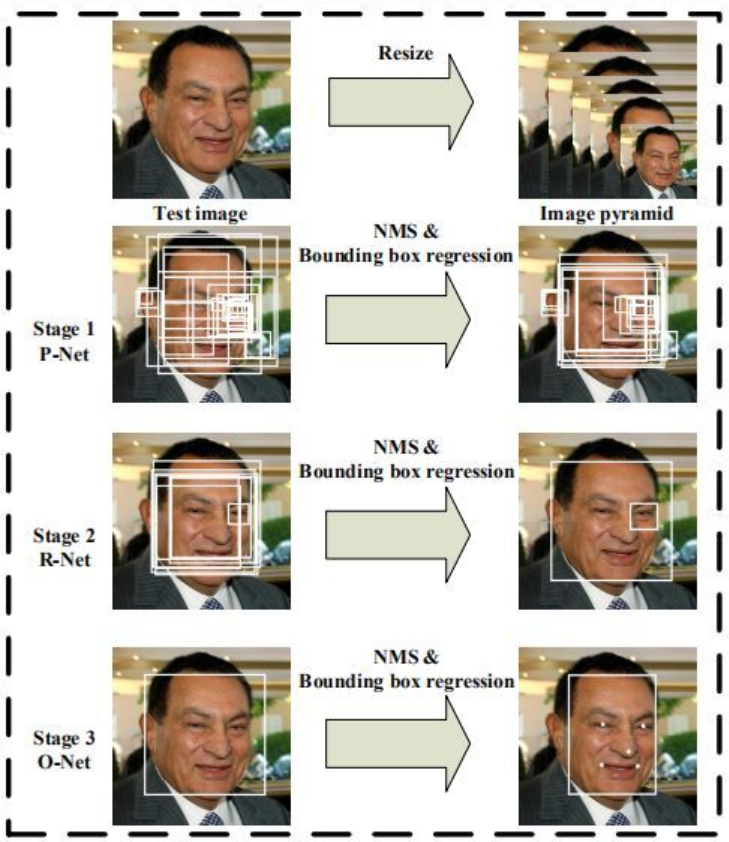
输入阶段:为应对目标多尺度问题,将原始图像resize到不同尺寸,构建图像金字塔,作为三阶级联架构的输入,这样处理可以更好地检测大小不一的人脸。
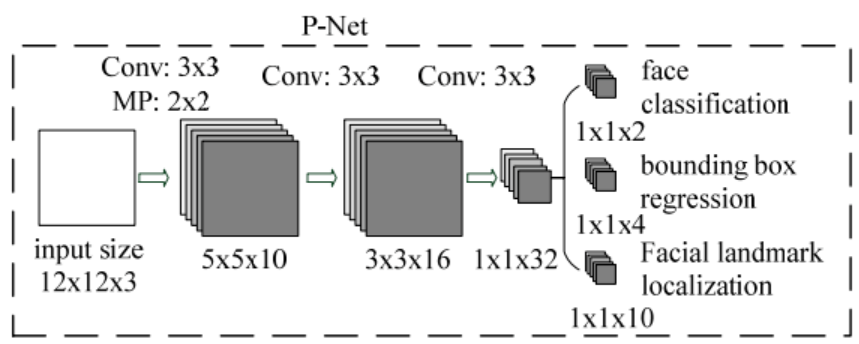
第一阶段:通过一个全部由卷积层组成的CNN,取名P-Net,获取候选人脸框、关键点坐标和人脸分类(是人脸或不是),之后采用NMS过滤掉高重叠率的候选窗口。如下图所示:
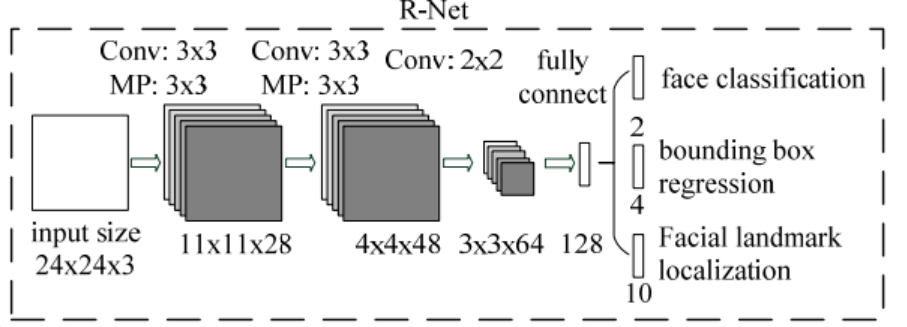
第二阶段:第一阶段输出的候选人脸框作为更为复杂的R-Net网络的输入,R-Net进一步筛除大量错误的候选人脸框,同样也通过NMS过滤掉高重叠率的候选窗口。如下图所示:
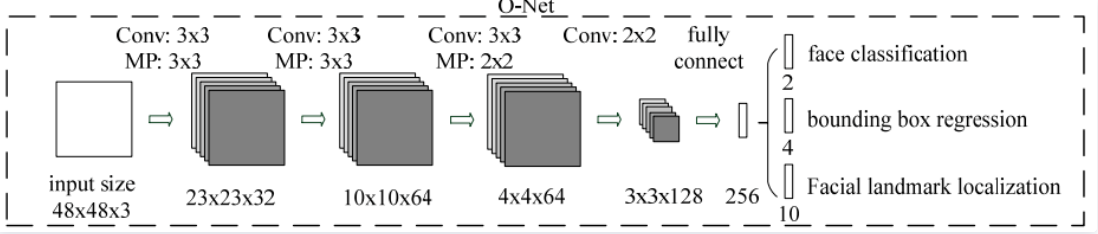
第三阶段:与第二阶段类似,最终网络输出人脸框坐标、关键点坐标和人脸分类(是人脸或不是)。如下图所示:
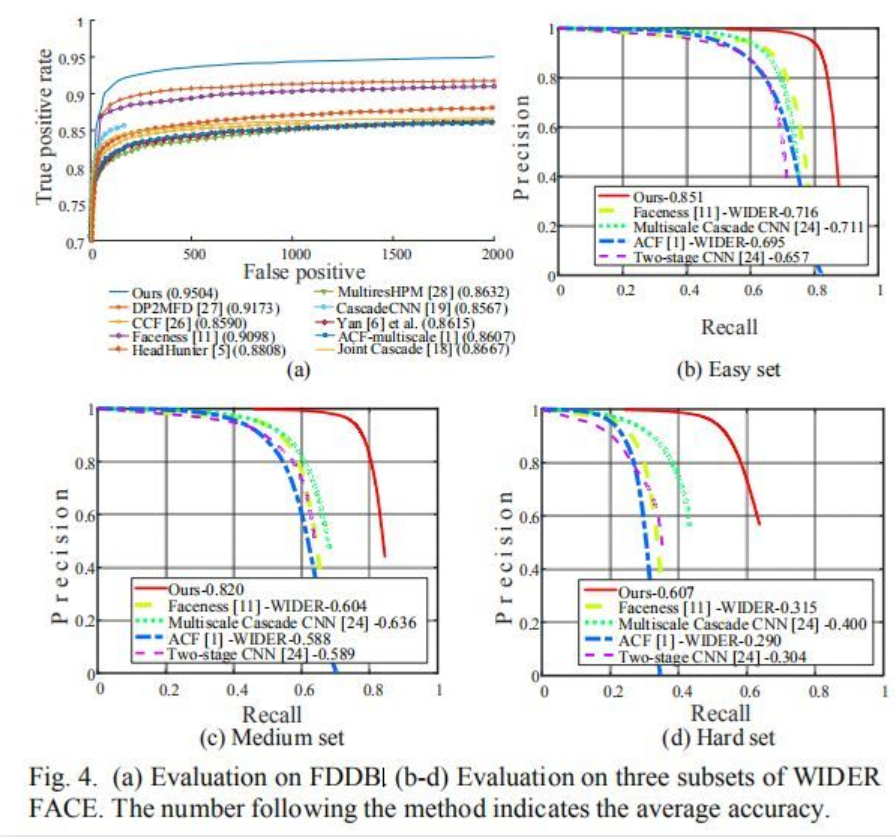
MTCNN通过三级的级联卷积神经网络对任务进行从粗到细的处理,还提出在线困难样本生成策略(online hard sample mining )可以进一步提升性能。兼并了速度与准确率,速度在GPU上可以达到99FPS,在 FDDB数据集上可以达到95.04准确率,具体如下图所示:
二、人脸对齐(部分参考于GraceDD的博客文章)
人脸对齐通过人脸关键点检测得到人脸的关键点坐标,然后根据人脸的关键点坐标调整人脸的角度,使人脸对齐,由于输入图像的尺寸是大小不一的,人脸区域大小也不相同,角度不一样,所以要通过坐标变换,对人脸图像进行归一化操作。人脸关键点检测有很多算法可以使用包括:ASM、AAM、DCNN 、TCDCN 、MTCNN 、TCNN、TCNN等,这里就不详细介绍,主要说一下得到人脸关键点之后如何进行人脸对齐,是所有人脸达到归一化效果,该过程如下图所示:

该过程涉及到图像的仿射变换,简单来说,“仿射变换”就是:“线性变换”+“平移”,即坐标的变换。假如我们希望人脸图片归一化为尺寸大小600600,左眼位置在(180,200),右眼位置在(420,200)。 这样人脸中心在图像高度的1/3位置,并且两个眼睛保持水平,所以我们选择左眼角位置为( 0.3width, height / 3 ),右眼角位置为(0.7*width , height / 3) 。
利用这两个点计算图像的变换矩阵(similarity transform),该矩阵是一个2*3的矩阵,如下:
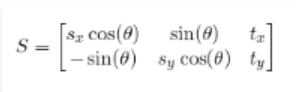
如果我们想对一个矩形进行变换,其中x、y方向的缩放因为分别为sx,sy,同时旋转一个角度 ,然后再在x方向平移tx, 在y方向平移ty
利用opencv的estimateRigidTransform方法,可以获得这样的变换矩阵,但遗憾的是,estimateRigidTransform至少需要三个点,所以我们需要构选第三个点,构造方法是用第三个点与已有的两个点构成等边三角形,这样第三个点的坐标为:
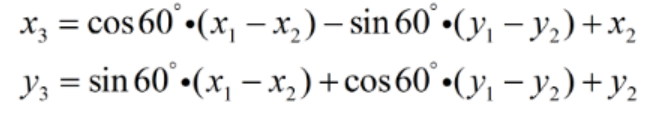
代码如下:
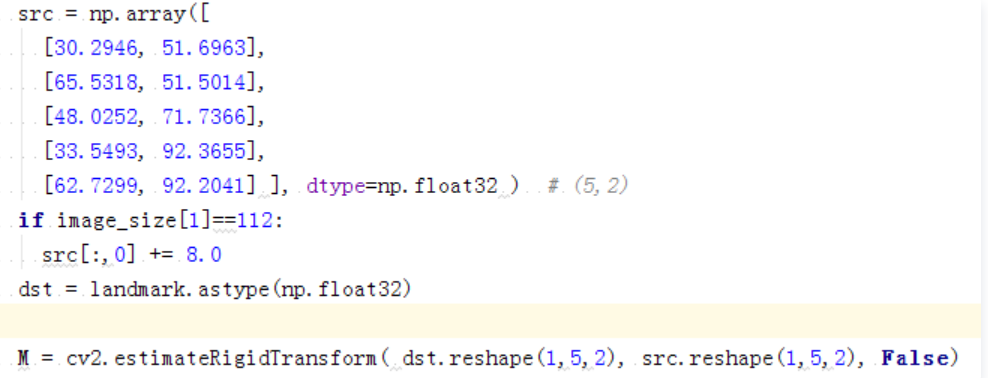
经过上一步的处理之后,所有的图像都变成一样大小,并且又三个关键点的位置是保持一致的,但因为除了三个点对齐了之外,其他点并没有对齐。所以根据得到的变换矩阵对剩下所有的点进行仿射变换,opencv代码如下所示:
![]()
img为输入图像;
warped为变换后图像,类型与src一致;
M为变换矩阵,需要通过其它函数获得,当然也可以手动输入;
Image_size为输出图像的大小;
三、 总结
本期文章主要介绍了人脸检测与对齐的相关算法,下一期我给大家介绍一下人脸表征的相关算法,即通过深度学习提取人脸特征,通过比较人脸特征进行人脸识别与验证。
参考文献:
- 【1】 S.Z.Li, L.Zhu, Z.Q.Zhang, A.Blake, H.J.Zhang, H.Y.Shum. Statistical learning of multi-view face detection. In: Proceedings of the 7-th European Conference on Computer Vision. Copenhagen, Denmark: Springer, 2002.67-81.
- 【2】Li H, Lin Z, Shen X, et al. A convolutional neural network cascade for face detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 5325-5334.
- 【3】Yang S, Luo P, Loy C C, et al. Faceness-Net: Face detection through deep facial part responses[J]. IEEE transactions on pattern analysis and machine intelligence, 2017.
- 【4】Yang S, Luo P, Loy C C, et al. From facial parts responses to face detection: A deep learning approach[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 3676-3684.
- 【5】Sun Y, Wang X, Tang X. Deep convolutional network cascade for facial point detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2013: 3476-3483.
- 【6】Zhang K, Zhang Z, Li Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
系列3:人脸表征
一、人脸表征
把人脸图像通过神经网络,得到一个特定维数的特征向量,该向量可以很好地表征人脸数据,使得不同人脸的两个特征向量距离尽可能大,同一张人脸的两个特征向量尽可能小,这样就可以通过特征向量来进行人脸识别。

二、论文综述
1. DeepFace:
2014年论文DeepFace: Closing the Gap toHuman-Level Performance in Face Verification提出了DeepFace算法,第一个真正将大数据和深度学习神经网络结合应用于人脸识别与验证。在该人脸识别模型中分为四个阶段:人脸检测 => 人脸对齐 => 人脸表征 => 人脸分类,在LFW数据集中可以达到97.00%的准确率。
(1)人脸检测与对齐:该模型使用3D模型来将人脸对齐,该方法过于繁琐,在实际应用中很少使用,经过3D对齐以后,形成的图像都是152×152的图像,具体步骤如下图。
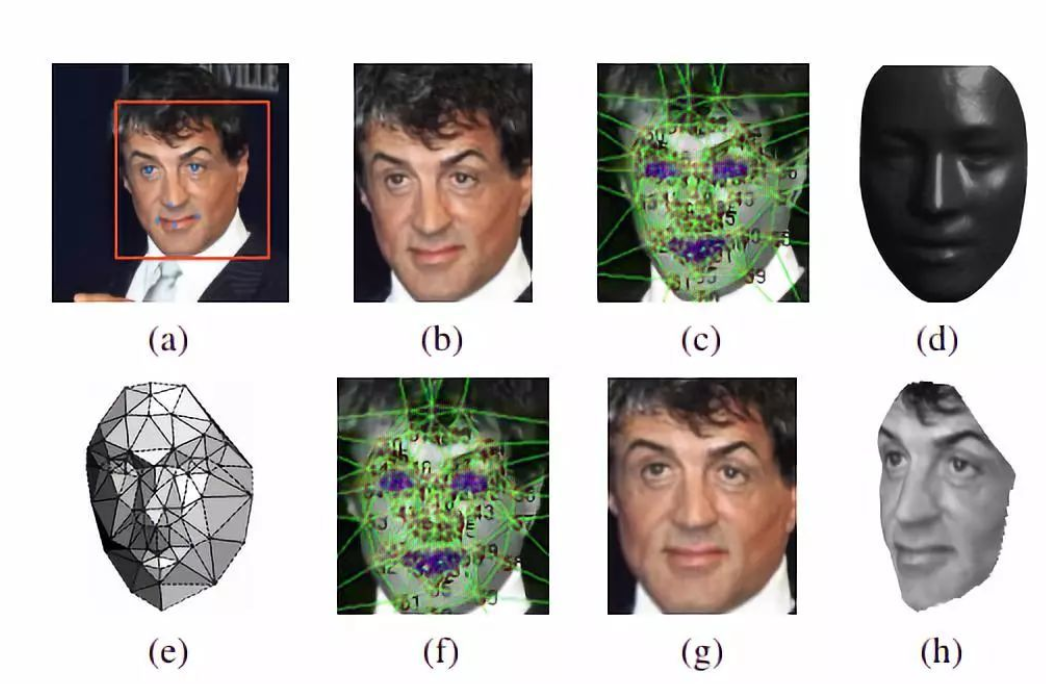
分为如下几步:
a. 人脸检测,使用6个基点 b. 二维剪切,将人脸部分裁剪出来 c. 67个基点,然后Delaunay三角化,在轮廓处添加三角形来避免不连续 d. 将三角化后的人脸转换成3D形状 e. 三角化后的人脸变为有深度的3D三角网 f. 将三角网做偏转,使人脸的正面朝前。 g. 最后放正的人脸 h. 一个新角度的人脸(在论文中没有用到)
(2)人脸表征:人脸表征使用了5个卷积层和1个最大池化层、1个全连接层,如下图所示。前三层的目的在于提取低层次的特征,为了网络保留更多图像信息只使用了一层池化层;后面三层都是使用参数不共享的卷积核,因为主要是因为人脸不同的区域的特征是不一样的,具有很大的区分性,比如鼻子和眼睛所表示的特征是不一样的,但是使用参数不共享的卷积核也增加了模型计算量以及需要更多的训练数据。最后输出的4096维向量进行L2归一化。

a. Conv:32个11×11×3的卷积核
b. max-pooling: 3×3, stride=2
c. Conv: 16个9×9的卷积核
d. Local-Conv: 16个9×9的卷积核,Local的意思是卷积核的参数不共享
e. Local-Conv: 16个7×7的卷积核,参数不共享
f. Local-Conv: 16个5×5的卷积核,参数不共享
g. Fully-connected: 4096维
h. Softmax: 4030维
(3)分类:论文介绍了两种方法进行分类,加权的卡方距离和使用Siamese网络结构,设f1和f2为特征向量,上一个步骤的输出,则有:
①加权卡方距离:计算公式如下,加权参数由线性SVM计算得到:
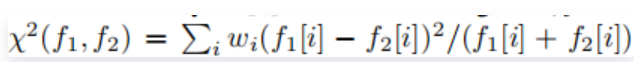
②Siamese网络:网络结构是成对进行训练,得到的特征表示再使用如下公式进行计算距离:
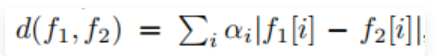
2. DeepID1:
DeepID1 是2014年Deep LearningFace Representation from Predicting 10,000 Classes一文提出的,是DeepID三部曲的第一篇。DeepID1 使用softmax多分类训练,主要思想第一个是数据集的增大,包括训练集使用celebface,包含87628张图片,5436个人脸,增大了训练集;使用多尺寸输入,通过5个landmarks将每张人脸划分成10regions,每张图片提取60patches=10regions3scales2(RGB orgray),第二个是网络结构,DeepID提取的人脸特征就是一个由连接第三层与第四层组成的全连接层特征,如下图所示,每个patches经过这个cnn网络,第四层的特征更加全局化(global),第三层的特征更加细节,因此DeepID连接了两者,以求同时包含全局,细节信息。
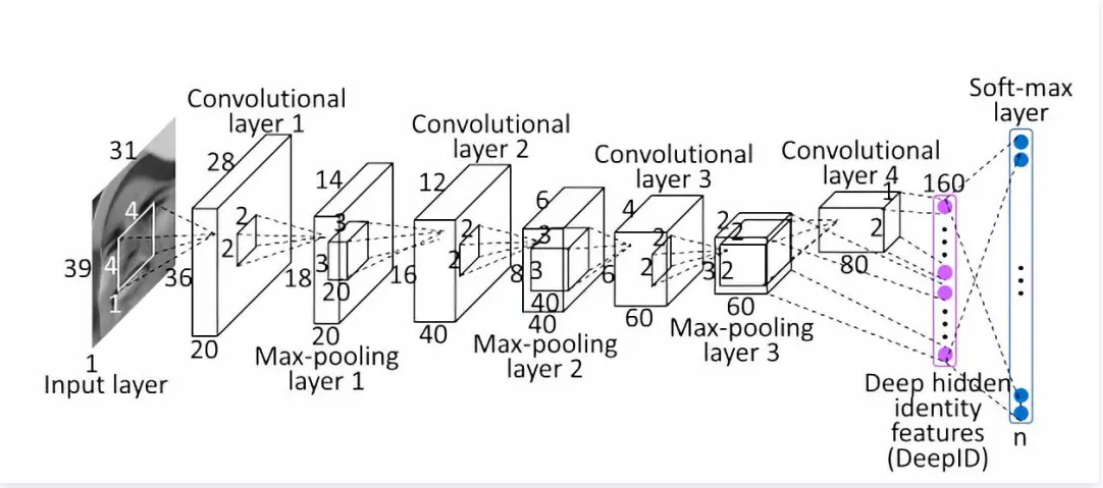
60个patches使用60个CNN,每个CNN提取2*160=320维特征(与水平翻转一起输入),总网络模型如下图所示,最后分别使用联合贝叶斯算法与神经网络进行分类,并比较结果。
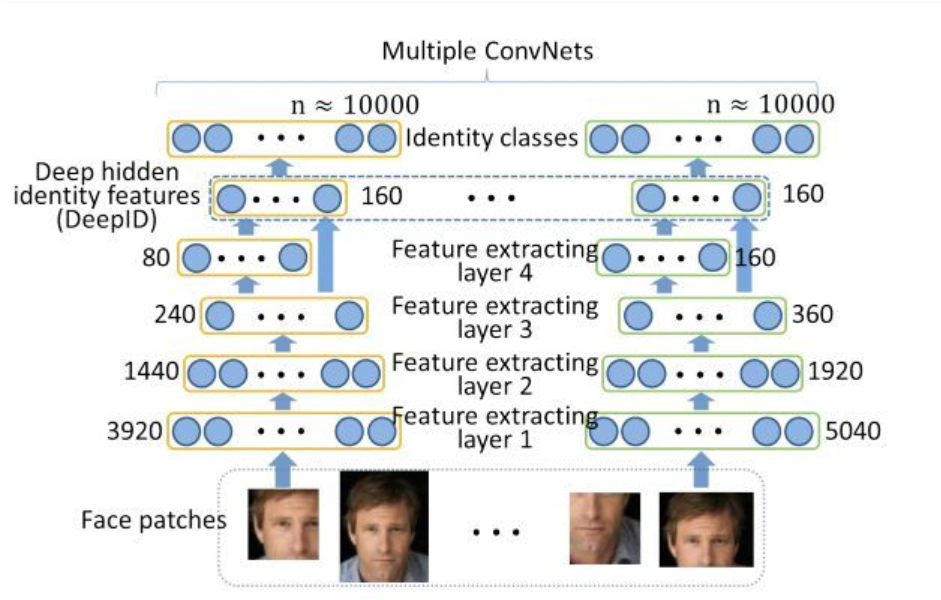
模型最终以CelebFaces+中202,599图像作为训练集, patch数提升为100(10r10s2) ,特征数提升为1001602=32000 然后使用PCA降为150维 ,使用联合贝叶斯算法进行验证, 最终在LFW上达到97.20%的验证准确率。
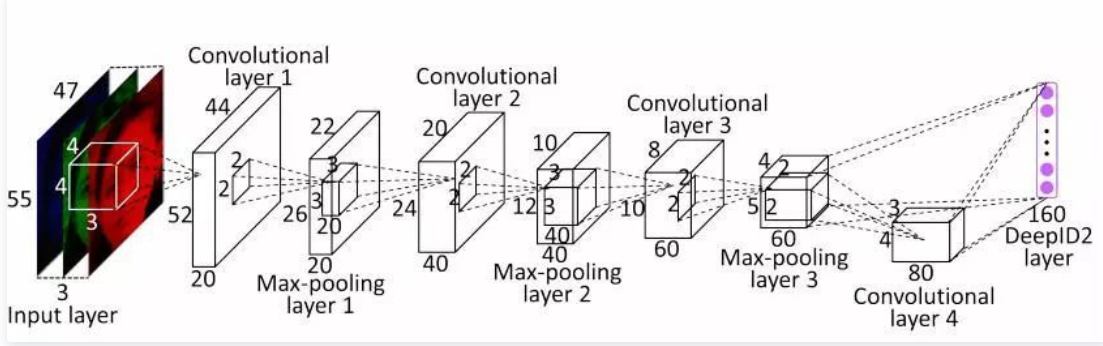
3. DeepID2:
DeepID2是Deep Learning Face Representationby Joint Identification-Verification一文提出的,对DeepID1进行了进一步的改进,提出了contrastive loss,在分类任务,我们需要的是减少类内差距(同一人脸),增加类间差距(不同人脸),softmax loss分类的监督信号可以增大类间差距,但是却对类内差距影响不大,所以DeepID2加入了另一个loss,contrastive loss,从而增加验证的监督信号,就可以减少类内差距。
网络结构类似DeepID1,不同之处在于使用了两种不同的损失函数,网络结构如下图所示。
损失函数:
①分类信号,Softmax loss。
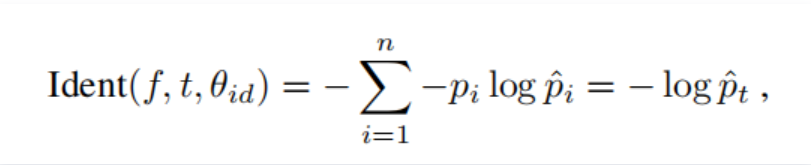
②验证信号,contrastiveloss,使用l2范数距离表示,m为阈值不参与训练,括号内的θve={m},该损失函数可以让类间的距离给定一个限制margin,即m大小的距离。
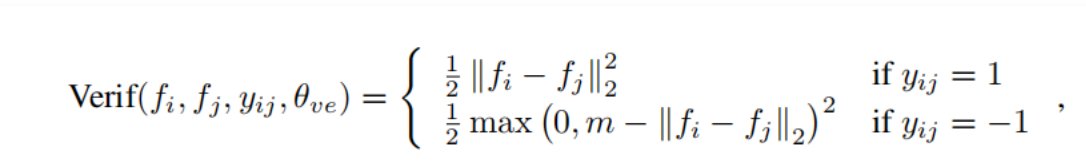
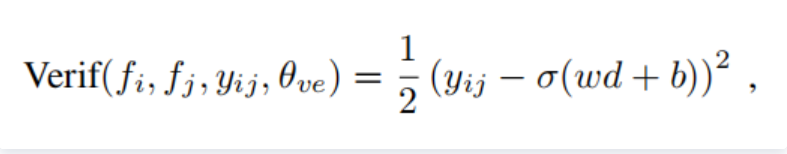
两loss的组合方式: 首先使用2个输入,计算Softmax loss和contrastive loss,总损失为二者通过λ加权求和,通过总损失来执行梯度下降更新卷积参数,通过Softmax loss来更新softmax层的参数。
整个模型使用celebrate+数据集训练,每张图片使用了21 facial landmarks,分成200patches(20regions5scales2RGB&Gray),水平翻转后变为400patches,使用了200个卷积神经网络,提取400(2002)个Deepid2特征,使用贪婪算法降为25个Deepid2特征,使用PCA将25160Deepid2特征降为180维,最后使用联合贝叶斯算法进行验证,最终在LFW上得到的最终准确率是98.97%,使用7组25个Deepid2特征,SVM融合可得到准确率为99.15% 。DeepID2在2014 年是人脸领域非常有影响力的工作,也掀起了在人脸领域引进 MetricLearning 的浪潮。
4. DeepID2+:
DeepID2+源于论文Deeply learned facerepresentations are sparse, selective, and robust,DeepID2+是对DeepID2的改进。①卷积层在原来基础上再增加128维,第四层全连接层从160增加到512,训练数据增加了CelebFaces+ dataset,WDRef等,有12000个人脸的大约290,000张图片; ②每个卷积层的后面都加了一个512为的全连接层,并添加contrastive loss监督信号,而不仅在第四层全连接层上有 。网络结构如下图所示。
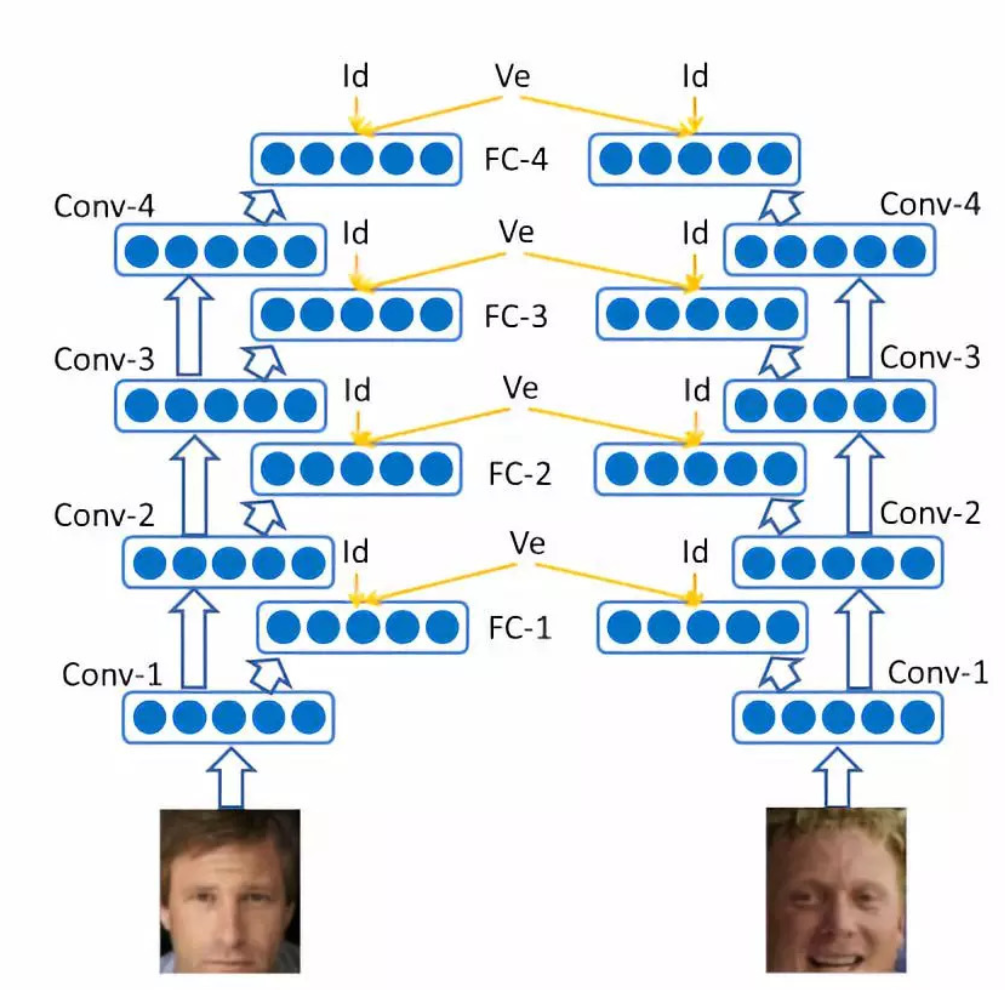
最终在LFW数据集上准确率为99.47%。
5. DeepID3:
DeepID3源于2015年的Deepid3:Face recognition with very deep neural networks论文,该论文探究了复杂神经网络对人脸识别的作用。论文研究VGG与GoogleNet用于人脸识别的效果,论文在VGG和GooLeNet的基础上进行构建合适的结构,使得方便人脸识别。结果发现DeepID3的结果和DeepID2+相当,可能是由于数据集的瓶颈,需要更大的数据才能有更好的提升,两个网络结构如下图所示。
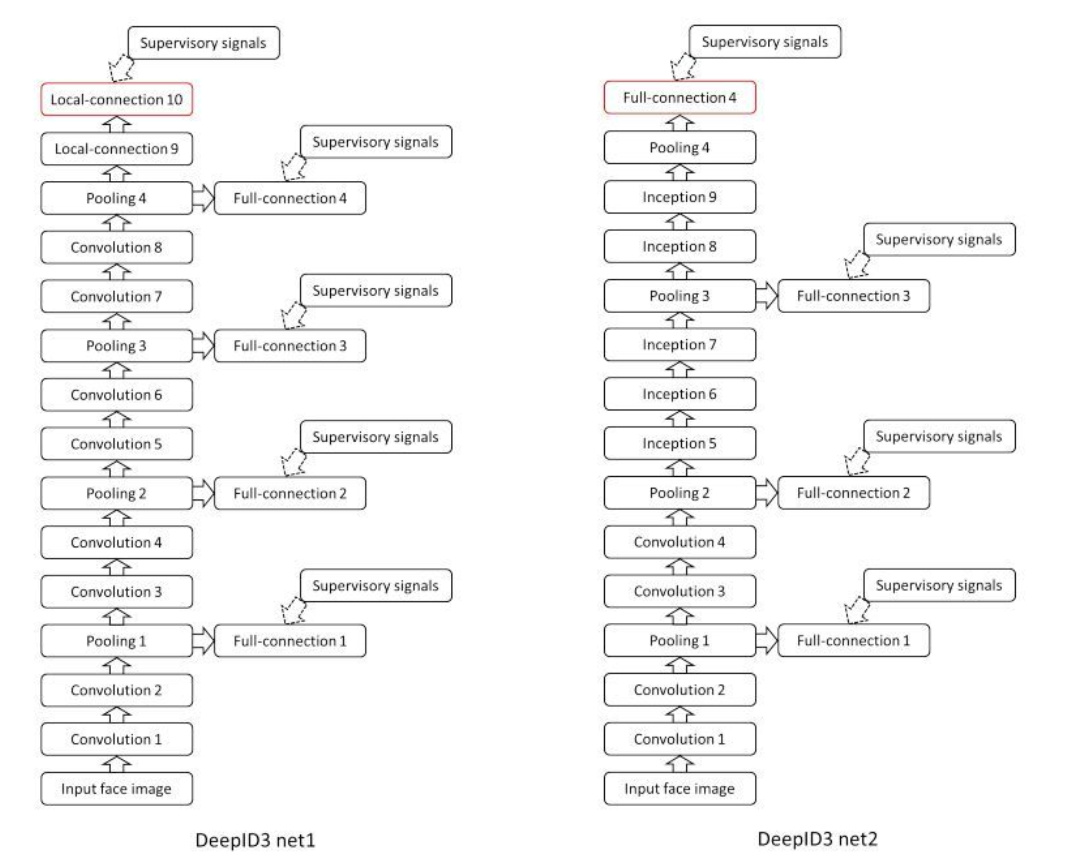
网络输出使用PCA降维到300维的向量,使用联合贝叶斯算法进行验证,最终在LFW上得到的最终准确率是99.53%。
6. FaceNet:
FaceNet由论文Facenet: A unified embedding forface recognition and clustering提出,这篇 2015 年来自 Google 的 论文同样具有非常大的影响力,不仅仅成功应用了 TripletLoss 在 benchmark 上取得state-of-art 的结果,更因为他们提出了一个绝大部分人脸问题的统一解决框架,即:识别、验证、搜索等问题都可以放到特征空间里做,需要专注解决的仅仅是如何将人脸更好的映射到特征空间。FaceNet在DeepID的基础上,将 ContrastiveLoss 改进为 Triplet Loss,去掉softmaxloss。FaceNet实验了ZFNet类型网络和Inception类型网络,最终Inception类型网络效果更好,网络结构如下图所示。
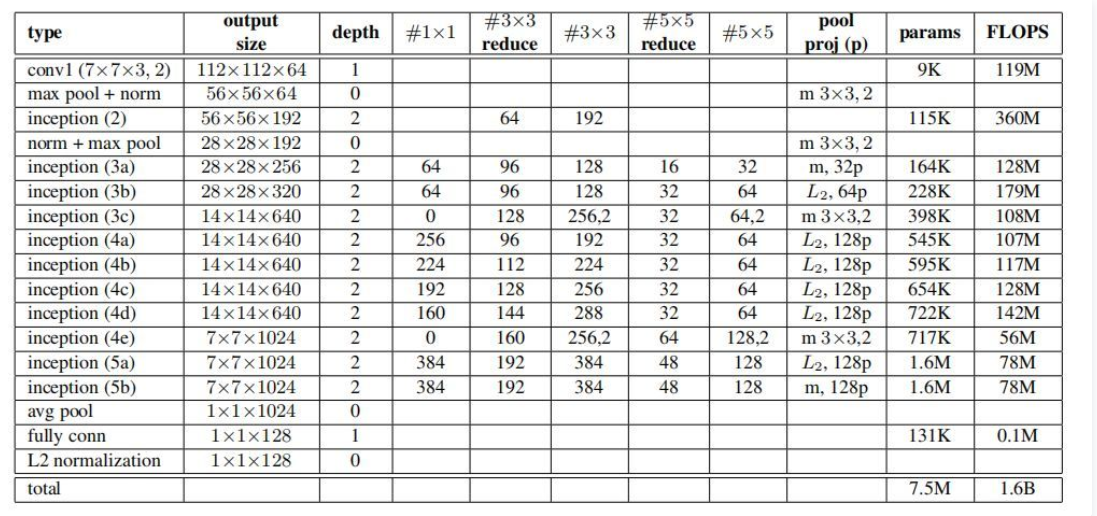
FaceNet没有使用PCA降维,而是在网络中直接训练输出128维的向量,用全连接层来完成降维,最后的128维的向量经过Triplet Loss。
Triplet Loss输入不再是 Image Pair,而是三张图片(Triplet),分别为 Anchor Face(xa),Negative Face(xn)和 Positive Face(xp)。Anchor 与 Positive Face 为同一人,与 Negative Face 为不同人,在特征空间里 Anchor 与 Positive 的距离要小于 Anchor 与 Negative 的距离,且相差超过一个 Margin Alpha。
loss的目标为:
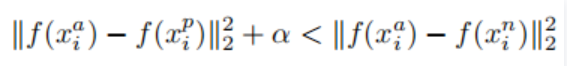
总loss公式为:
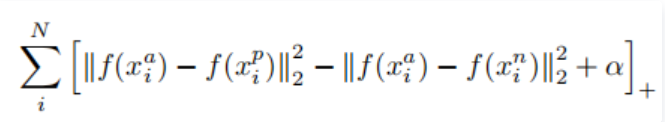
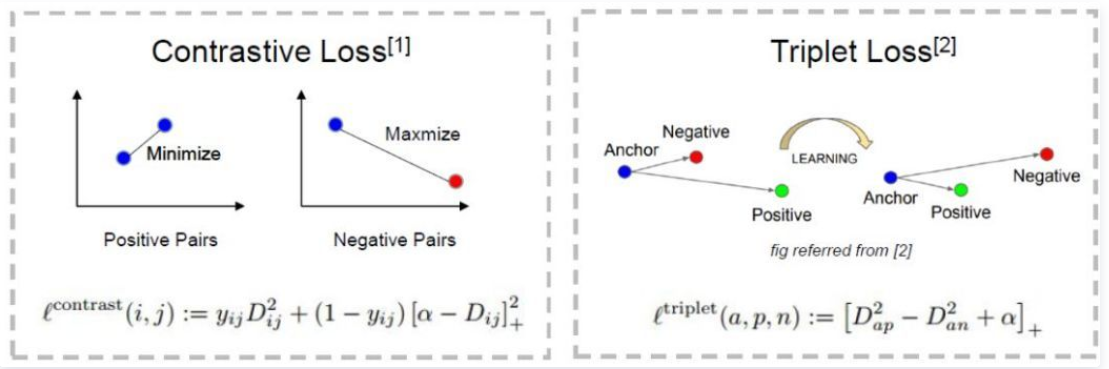
Contrastive Loss与Triplet Loss的比较, Contrastive Loss目标是减少类内差距(两个蓝点),增加类间差距(蓝点与红点);Triplet Loss则是输入三张图片,Anchor 与 Positive 的距离要小于 Anchor 与 Negative 的距离,且相差超过一个 Margin Alpha,即Triplet Loss同时约束了两个距离。
最后FaceNet在LFW数据集上达到了99.63%的准确率。
基于 ContrastiveLoss 和 Triplet Loss 的 MetricLearning 符合人的认知规律,在实际应用中也取得了不错的效果,但同时也有很多问题,由于ContrastiveLoss 和 Triplet Loss 的训练样本都基于pair 或者 triplet 的,可能的样本数是 O(N2) 或者 O (N3) 的,所以模型需要很久的计算才能拟合并且训练集需要足够大。
三、总结
本期文章主要介绍人脸表征相关算法和论文综述,主要是2014年到2016年的研究成果, ContrastiveLoss 和 Triplet Loss在实际应用中也取得了很好的效果,但是也有很多问题,由于Contrastive Loss 和 Triplet Loss 的训练样本都基于 pair 或者 triplet 的,可能的样本数是 O (N2) 或者 O (N3) 的,所以模型需要很久的计算才能拟合并且训练集要足够大,所以在之后的人脸识别研究中,大部分在于loss函数的研究,这部分将会在下一期给大家介绍。
参考文献:
- 【1】 Taigman Y, Yang M, Ranzato M A, et al.Deepface: Closing the gap to human-level performance in faceverification[C]//Proceedings of the IEEE conference on computer vision andpattern recognition. 2014: 1701-1708.
- 【2】Sun Y, Wang X, Tang X. Deep learning facerepresentation from predicting 10,000 classes[C]//Proceedings of the IEEEconference on computer vision and pattern recognition. 2014: 1891-1898.
- 【3】Sun Y, Chen Y, Wang X, et al. Deeplearning face representation by joint identification-verification[C]//Advancesin neural information processing systems. 2014: 1988-1996.
- 【4】Sun Y, Liang D, Wang X, et al. Deepid3:Face recognition with very deep neural networks[J]. arXiv preprintarXiv:1502.00873, 2015.
- 【5】Simonyan K, Zisserman A. Very deepconvolutional networks for large-scale image recognition[J]. arXiv preprintarXiv:1409.1556, 2014.
- 【6】Szegedy C, Liu W, Jia Y, et al. Goingdeeper with convolutions[C]//Proceedings of the IEEE conference on computervision and pattern recognition. 2015: 1-9.
- 【7】Sun Y, Wang X, Tang X. Deeply learned facerepresentations are sparse, selective, and robust[C]//Proceedings of the IEEEconference on computer vision and pattern recognition. 2015: 2892-2900.
- 【8】Schroff F, Kalenichenko D, Philbin J.Facenet: A unified embedding for face recognition andclustering[C]//Proceedings of the IEEE conference on computer vision andpattern recognition. 2015: 815-823.
系列4:人脸表征-续
一、人脸表征
把人脸图像通过神经网络,得到一个特定维数的特征向量,该向量可以很好地表征人脸数据,使得不同人脸的两个特征向量距离尽可能大,同一张人脸的两个特征向量尽可能小,这样就可以通过特征向量来进行人脸识别。

二、论文综述
1. L-Softmax:
Softmax Loss函数被广泛应用于深度学习,较为简单实用,但是它并不能够明确引导神经网络学习区分性较高的特征。L-Softmax能够有效地引导网络学习使得样本类内距离较小、类间距离较大的特征,L-Softmax不但能够调节类间距离的间隔(margin)大小,而且能够防止过拟合。
L-Softmax是对softmax loss的改进,softmax loss公式如下所示:
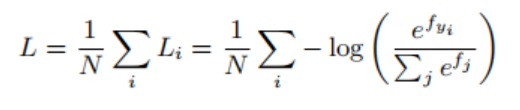
其中 fj 表示最终全连接层的类别输出向量 f的第 j个元素, N为训练样本的个数,则 fyi可以表示为 fyi=WTyi xi,其中 0≤θj≤π,最终的损失函数可得:
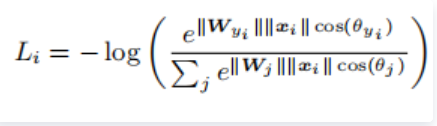
softmax的目的是使得WT1x>WT2x,即 ∥W1∥∥x∥cos(θ1)>∥W2∥∥x∥cos(θ2),从而得到输入x(来自类别1)输出正确的分类结果。L-Softmax通过增加一个正整数变量m,从而产生一个决策余量,能够更加严格地约束上述不等式,即:
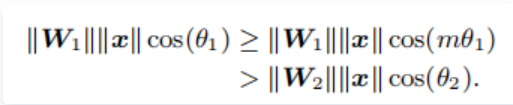
其中0≤θ1<π/m。如果W1和W2能够满足∥W1∥∥x∥cos(mθ1)>∥W2∥∥x∥cos(θ2),那么就必然满足∥W1∥∥x∥cos(θ1)>∥W2∥∥x∥cos(θ2),这样的约束对学习W1和W2的过程提出了更高的要求,在训练学习过程中,类间要比之前多了一个m的间隔,从而使得1类和2类有了更宽的分类决策边界。这种Margin Based Classification使得学习更加的困难,从而使类间距离增加了一个margin距离,L-Softmax loss的总公式如下:
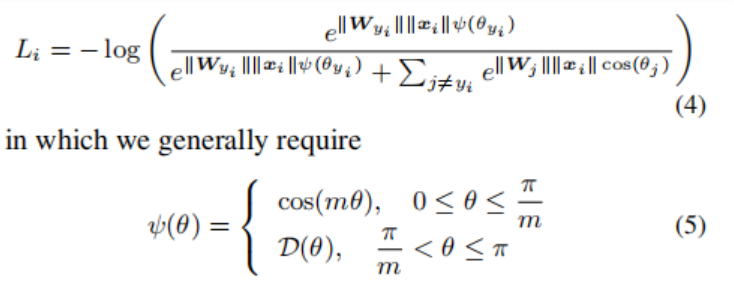
当m越大时,分类的边界越大,学习难度当然就越高。
论文仅使用了WebFace数据集作为训练集和一个简单的卷积网络,就在LFW上达到了98.71%的正确率,证明了L-Softmax loss取得了比softmax loss更好的结果。
2. SphereFace :
SphereFace在MegaFace数据集上识别率在2017年排名第一,提出A-Softmax Loss使人脸识别达到不错的效果。A-Softmax Loss基于softmax loss和L-Softmax loss,在二分类模型中,softmax loss为:
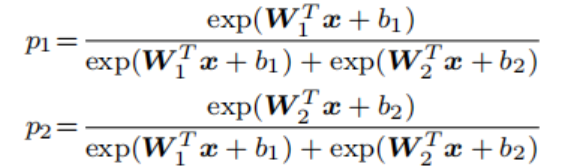
如果x为类别一,则希望p1>p2,则二分类的划分函数为:
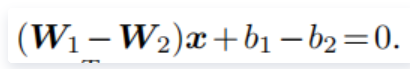
权重归一化||w||为1,b为0,此时特征上的点映射到单位超球面上,则二分类的划分函数为:

然后使用与L-Softmax loss相同的原理,使
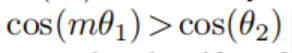
则A-Softmax Loss最终为:
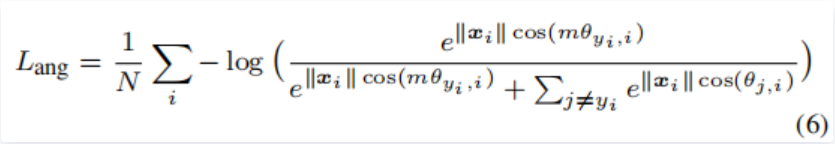
因此A-Softmax Loss是样本类别之间产生了角度距离,让决策函数更加严格并且更加具有可区分性。当m增大,角度距离也会增加。
A-Softmax与L-Softmax的最大区别在于A-Softmax的权重归一化了,而L-Softmax则没有。A-Softmax权重的归一化导致特征上的点映射到单位超球面上,A-Softmax仅仅能从角度上划分类别,而L-Softmax是在角度与长度方向进行考量,两个方向如果划分不一就会收到干扰,导致精度下降。
SphereFace使用的模型如下图所示:
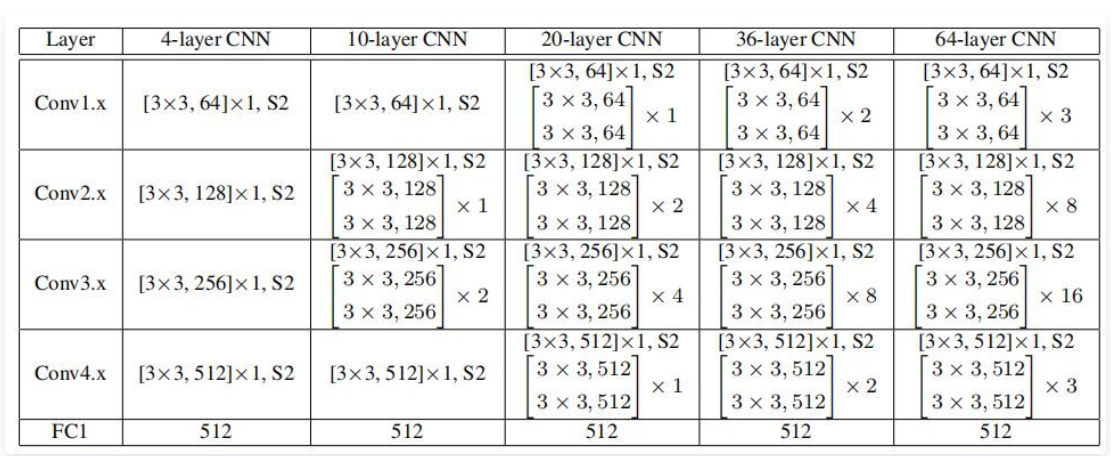
训练与测试过程如下图所示,在测试过程中使用余弦计算相似度:
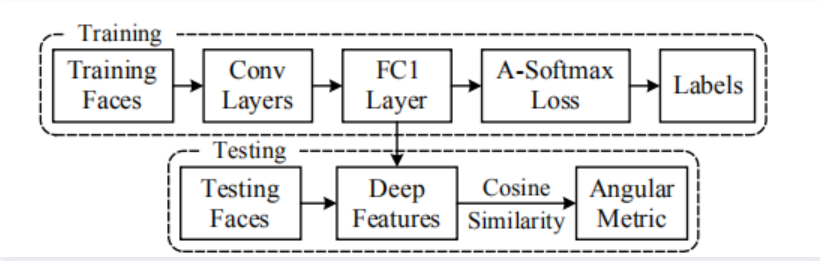
最终SphereFace在训练集较小的情况下,LFW数据集上准确率为99.42%。Sphereface效果很好,但是它不优美。在测试阶段,Sphereface通过特征间的余弦值来衡量相似性,即以角度为相似性的度量,在训练阶段,其实Sphereface的损失函数并不是在直接优化特征与类中心的角度,而是优化特征与类中心的角度在乘上一个特征的长度,这就造成了训练跟测试之间目标不一致。
3. Normface :
在优化人脸识别任务时,softmax本身优化的是没有归一化的内积结果,但是最后在预测的时候使用的一般是cosine距离或者欧式距离,这会导致优化目标和最终的距离度量其实并不一致。 Normface的核心思想是既然最后在特征对比的时候使用归一化的cosine距离,那么在训练的过程中把特征也做归一化处理,做了归一化之后,softmax的优化就变成了直接优化cosine距离了,归一化过程如下,其中e是为了防止除0的较小正数:
相应的损失函数如下:
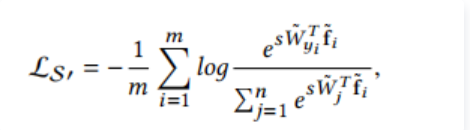
其中 W 是归一化的权重,f_i 是归一化的特征,参数 s 的引入是因为保证梯度大小的合理性,去掉bias是因为softmax之前的fc有bias的情况下会使得有些类别在角度上没有区分性但是通过bias可以区分,在这种情况下如果对feature做normalize,会使得中间的那个小类别的feature变成一个单位球形并与其他的feature重叠在一起,所以在feature normalize的时候是不能加bias的。
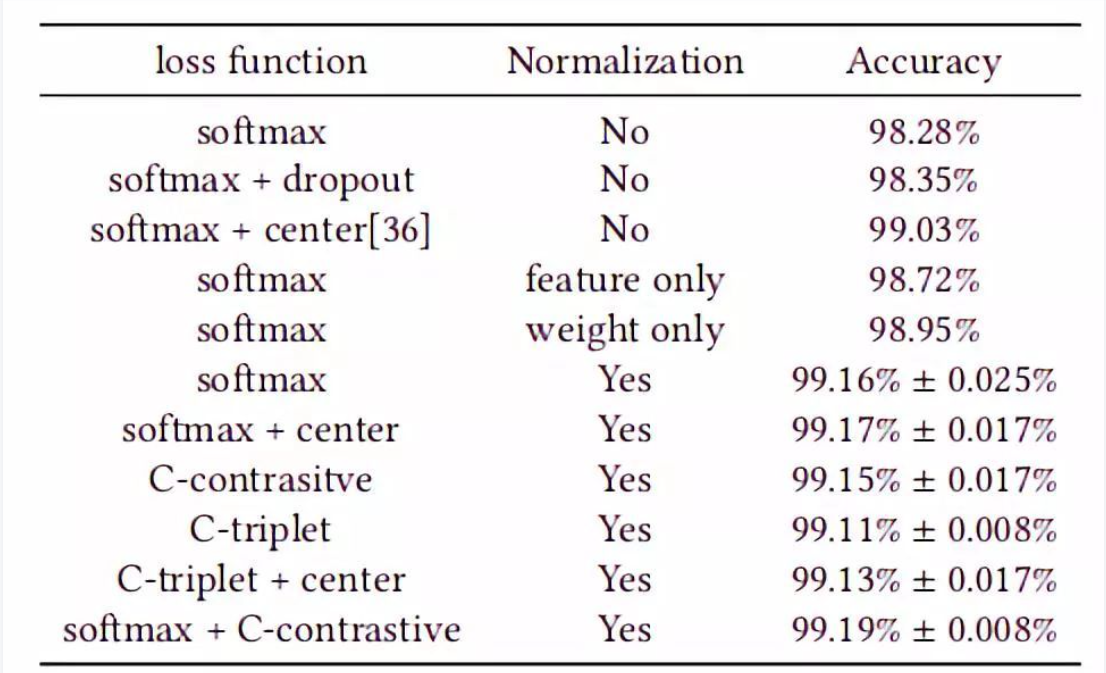
Normface使用了较小的模型使用多种loss训练,然后在LFW数据集上测试,证明了feature normalize的效果,结果如下:
4. CosFace :
Normface用特征归一化解决了Sphereface训练和测试不一致的问题。但是却没有了margin的惩罚,腾讯AI Lab的CosFace或者AM-softmax是在Normface的基础上引入了margin,损失函数为:
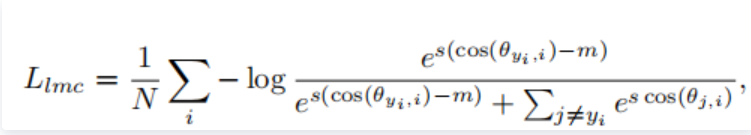
其中特征与权值都做了归一化:
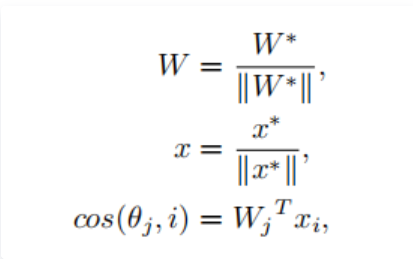
分类决策为:
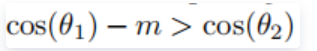
,比之前增加了m的margin,m 是一个超参数,控制惩罚的力度,m 越大,惩罚越强。
CosFace使用mtcnn进行人脸检测与对齐,人脸表征训练模型使用基于residual units 64层卷积网络的Sphere Face,在5M的训练集上训练,在LFW数据集上测试,精度达到99.73%。
5. ArcFace :
ArcFace源于论文Additive angular margin lossfor deep face recognition,也叫做InsightFace,论文基本介绍了近期较为流行的人脸识别模型,loss变化从softmax到AM-softmax,然后提出ArcFace,可以说起到了很好的综述作用,论文从三个方面探讨影响人脸识别模型精度的主要因素。
(1)数据:数据方面,论文探讨了各个数据集的数据质量和优缺点,并对MS-Celeb-1M,MegaFace FaceScrub做了清洗,清洗后的数据公开。
(2)网络:详细对比了不同的主流网络结构的性能,包括输入层尺寸大小、最后输出几层的不同结构、基本网络单元残差网络的不同结构、主干网络的不同模型。经过实验的证明,最后的网络结构:输入图片大小112x112;第一层convLayer 卷积核为33 stride 1时,网络输出77;主干网络使用ResNet100,并使用改进后的改进的残差网络结构,如下图;最后的几层输出层为最后一个卷积层后+BN-Dropout-FC-BN的结构。
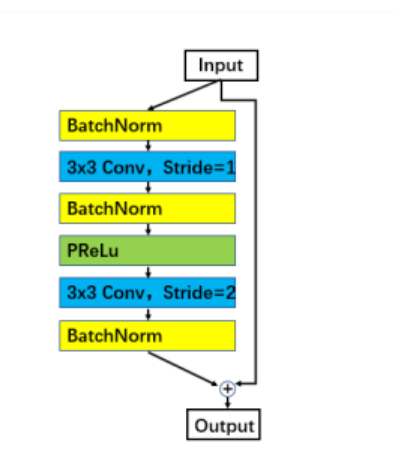
(3)损失函数:与 AM-softmax相比,区别在于Arcface引入margin的方式不同,损失函数为:
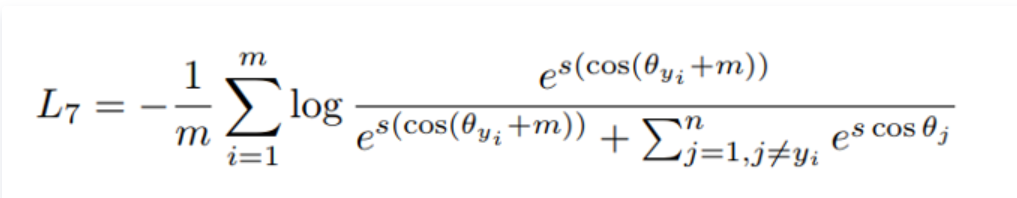
Arcface的m是在余弦里面,AM-softmax的在外面,ArcFace更为直观并且在超球面维度上有更清晰的解释。Arcface在VGG2和MS-Celeb-1M数据集上训练,在LFW数据集上精度达到99.83%。
三、总结
本期文章主要介绍人脸表征相关算法和论文综述,人脸检测、对齐、特征提取等这些操作都可以在静态数据中完成,下一期将给大家介绍在视频数据中进行人脸识别的另一个重要的算法,视频人脸跟踪的概念与方法。
参考文献:
- 【1】 Liu W, Wen Y, Yu Z, et al. Large-MarginSoftmax Loss for Convolutional Neural Networks[C]//ICML. 2016: 507-516.1708.
- 【2】Liu W, Wen Y, Yu Z, et al. Sphereface:Deep hypersphere embedding for face recognition[C]//The IEEE Conference onComputer Vision and Pattern Recognition (CVPR). 2017, 1: 1.
- 【3】Wang F, Xiang X, Cheng J, et al. Normface:l 2 hypersphere embedding for face verification[C]//Proceedings of the 2017 ACMon Multimedia Conference. ACM, 2017: 1041-1049.
- 【4】Wang F, Cheng J, Liu W, et al. Additivemargin softmax for face verification[J]. IEEE Signal Processing Letters, 2018,25(7): 926-930.
- 【5】Wang H, Wang Y, Zhou Z, et al. CosFace:Large margin cosine loss for deep face recognition[J]. arXiv preprintarXiv:1801.09414, 2018.
- 【6】Deng J, Guo J, Zafeiriou S. Arcface:Additive angular margin loss for deep face recognition[J]. arXiv preprintarXiv:1801.07698, 2018.
编辑整理 磐创AI技术团队
系列教程
AI系列
Hexo系列
[三万字教程]基于Hexo的matery主题搭建博客并深度优化完全一站式教程
- Hexo Docker环境与Hexo基础配置篇
- hexo博客自定义修改篇
- hexo博客网络优化篇
- hexo博客增强部署篇
- hexo博客个性定制篇
- hexo博客常见问题篇
- hexo博客博文撰写篇之完美笔记大攻略终极完全版
- Hexo Markdown以及各种插件功能测试
- markdown 各种其它语法插件,latex公式支持,mermaid图表,plant uml图表,URL卡片,bilibili卡片,github卡片,豆瓣卡片,插入音乐和视频,插入脑图,插入PDF,嵌入iframe
- 在 Hexo 博客中插入 ECharts 动态图表
- 使用nodeppt给hexo博客嵌入PPT演示
- GithubProfile美化与自动获取RSS文章教程
- Vercel部署高级用法教程
- webhook部署Hexo静态博客指南
- 在宝塔VPS上面采用docker部署waline全流程图解教程
- 自建Umami访问统计服务并统计静态博客UV/PV




